Accurate camera localization in existing LiDAR maps has gained popularity due to the combination of strengths in both LiDAR-based and camera-based methods. However, it still lacks approaches of robust end-to-end 2D-3D localization and strategies to handle the problem of significant differences in modality and appearance. To overcome these problems, we propose the I2D-Loc, a scene-agnostic and end-to-end trainable neural network that estimates a 6-DoF pose from an RGB image to an existing LiDAR map based on a paradigm of local optimization on an initial pose. Specifically, we first project the LiDAR map to the image plane according to a rough initial pose and utilize a depth completion algorithm to generate a dense depth image. We further design a confidence map to weight the features extracted from the dense depth to get a more reliable depth representation. Then, we propose to utilize a neural network to estimate the correspondence flow between depth and RGB images. Finally, we utilize the BPnP algorithm to estimate the 6-DoF pose, calculating the gradients of pose error and optimizing the front-end network parameters. Moreover, by decoupling the intrinsic camera parameters out of the end-to-end training process, I2D-Loc can be generalized to the images with different intrinsic parameters. Experiments on KITTI, Argoverse, and Lyft5 datasets demonstrate that the I2D-Loc can achieve centimeter localization performance.
Introduction
Accurate localization techniques are critical towards autonomous robots such as self-driving cars and drones. It refers to the process of finding the 6 degree-of-freedom (DoF) poses of robots by comparing online sensor measurements with the reference maps such as 3D point clouds. Currently, although GPS is the most widely used global positioning system, its accuracy and stability are limited due to the lack of direct line-of-sight to the satellites in urban environments. To alleviate these problems, some researchers propose to utilize sensors such as LiDARs, cameras, Inertial Measurement Units (IMUs) to achieve autonomous localization. LiDAR-based localization and mapping methods have achieved good performance because of the accurate range measurements and robustness to the changes of lighting condition and view angle. However, LiDAR sensors are currently expensive and heavy to be mounted on micro drones. An alternative is to use low-cost, lightweight, and commonly available cameras. Recent camera-based localization methods are well-developed and achieve promising accuracy. However, visual-based methods lack robustness over challenging conditions such as illumination, weather, and season changes over time. Therefore, if we can establish direct correspondences between visual images and existing LiDAR maps, the vision-based localization challenges will be greatly mitigated since the visual factors cannot influence LiDAR maps. Meanwhile, light-weight cameras can be located in the accurate 3D maps without a LiDAR sensor, thus the strengths of both LiDAR-based and camera-based methods can be maintained.
If we have the 2D-3D feature matching between LiDAR maps and images, the camera poses can be accurately estimated with PnP solver. However, the estimation of 2D-3D feature correspondences is challenging for two aspects: 1) Feature repeatability. Although there exists a large overlap between point clouds and the corresponding image, it is still hard to make sure the extracted image features (e.g., SIFT) and the 3D features (e.g., ISS) have a large proportion of repetitiveness and high location accuracy. Consequently, poor feature repeatability will result in many outlier matches. 2) Description difference. Point clouds are 3D data with geometric information while images are 2D data with texture information. This internal difference makes it challenging to establish a high-dimensional descriptor space for measuring the similarities. To overcome the modality gaps, prior works usually project 3D data into 2D space or reconstruct 3D point clouds from multi-view images to match in the same domain. In these ways, they alleviate modal gaps and appearance differences to some extent. Compared to matching in 3D space, we argue that matching in 2D space will give more stable dense correspondences and low CPU computation burden since it involves the simple 3D-2D projection, and later cross-modal correspondences can be estimated with GPU acceleration.
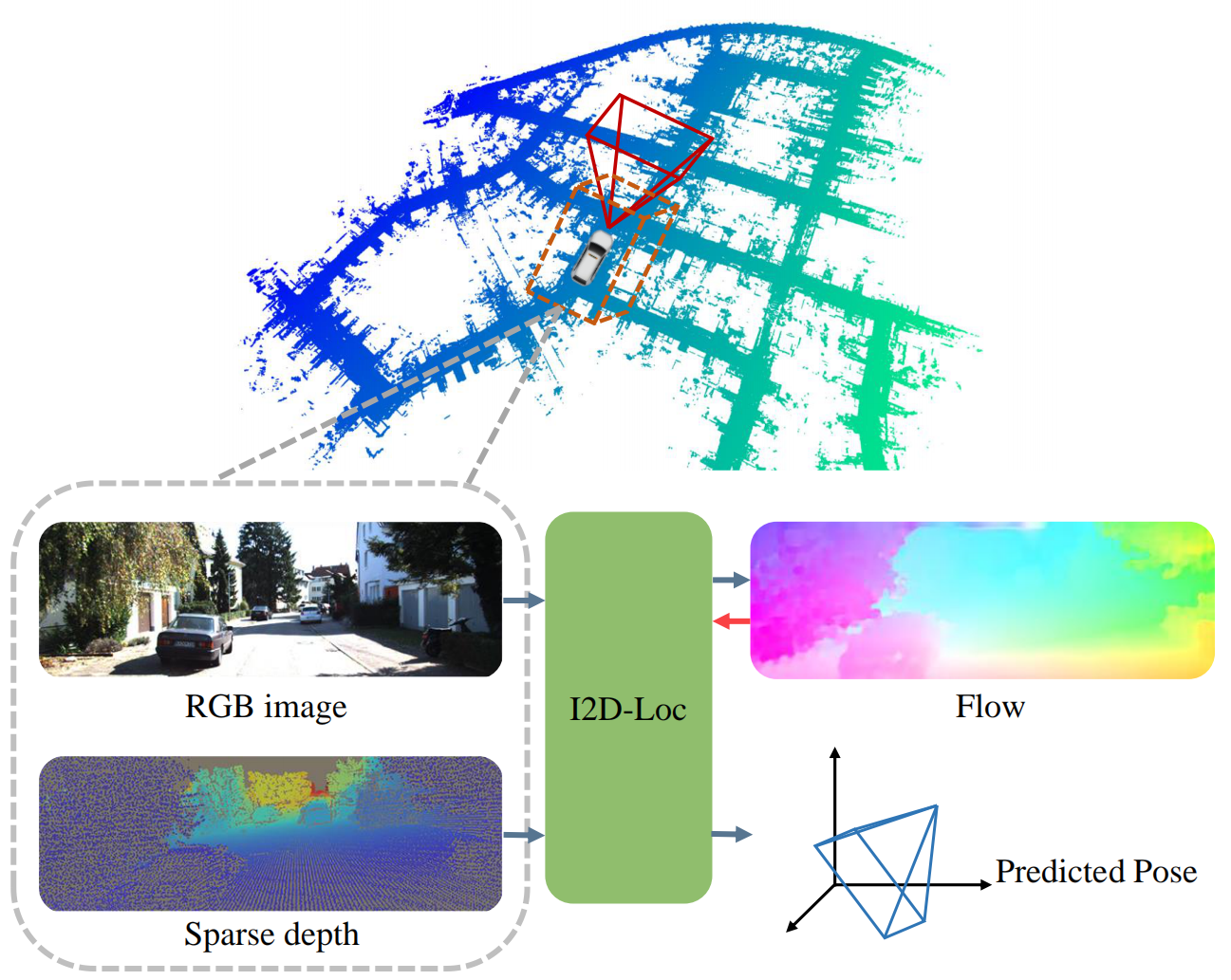
Figure 1. Pose estimation with I2D-Loc. Given a LiDAR point cloud map, a reference image and a rough initial pose, I2D-Loc can estimate the dense 2D pixel to 3D point correspondences, so as to estimate the accurate camera pose in the LiDAR map.)
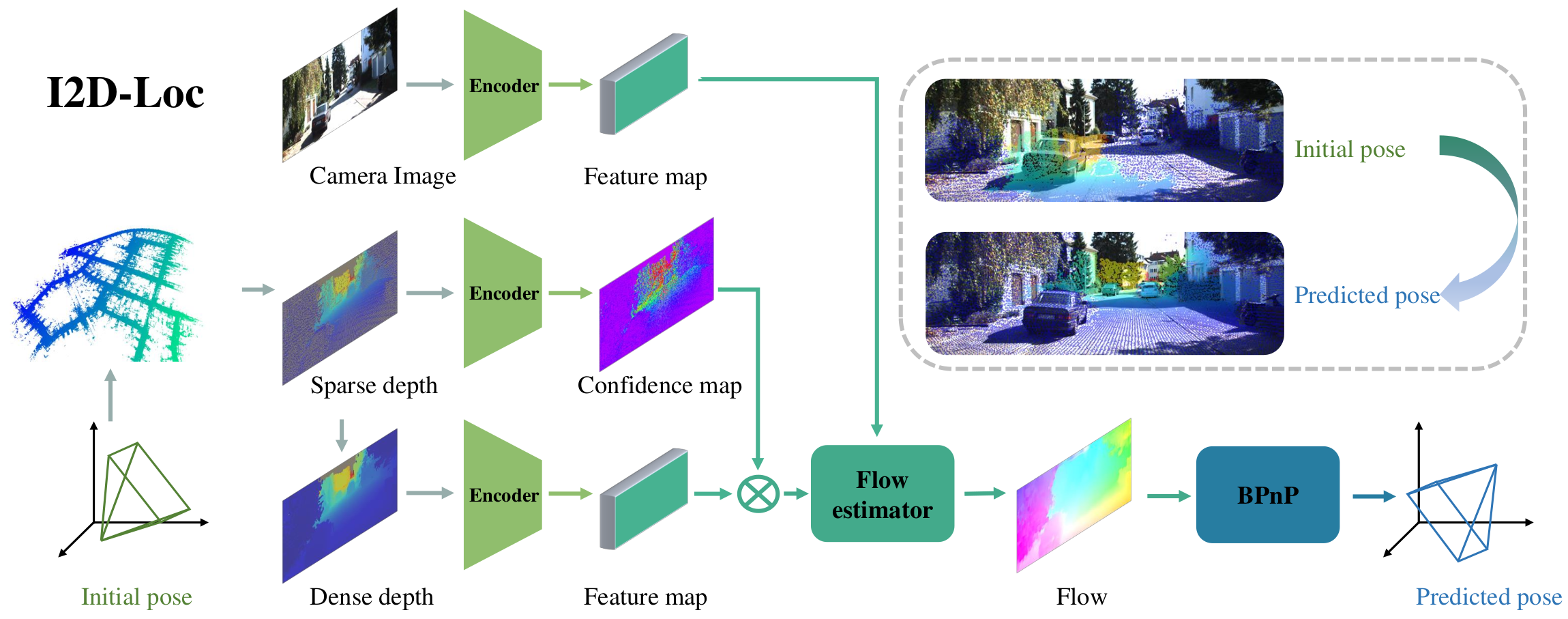
In this paper, we propose the I2D-Loc: a scene-agnostic and end-to-end trainable neural network that estimates a 6-DoF pose from an RGB image and an existing LiDAR map. The high-level overview is shown in Fig. 1. In our pipeline, we assume the initial camera pose in the LiDAR map is known, which is usually obtained via image retrieval, GPS, or the pose from the previous frame. With a rough pose, the proposed I2D-Loc can achieve 2D-3D pose tracking without accumulated drift problem. Specifically, we first project the 3D LiDAR map to obtain a sparse depth according to the initial pose and occlusion removal. Considering the sparsity of LiDAR point clouds, we design a simple but effective depth representation that uses a depth completion algorithm to obtain dense depth and a confidence map to weight the features extracted from the depth. Then we develop the cross-modal flow network to predict the correspondences between RGB images and LiDAR depth images. Finally, we connect the flow map with the BPnP module to estimate the camera pose in an end-to-end manner with robustness to the changes of intrinsic camera parameters.
Our contributions are three-folds:
We propose a simple but effective network for camera localization based on the local image-LiDAR depth registration with a pose initialization, which predicts the flow between an image and LiDAR depth to obtain 2D-3D correspondences. A BPnP module is used for calculating the gradients of the back-end pose estimation process, enabling our model to be trained end-to-end.
We design a novel LiDAR depth representation that uses a simple depth completion algorithm to acquire dense depth and utilizes a confidence map to weight the features extracted from the depth to enhance the depth features. It's a novel data enhancement strategy to alleviate the appearance difference between the RGB and depth images.
To evaluate the performance, we conduct experiments on several public datasets such as KITTI, Argoverse, and Lyft5, and the experiments demonstrate that I2D-Loc can achieve centimeter camera localization without pose drift. More importantly, the experimental results on mixed datasets demonstrate the generalization of I2D-Loc on new cameras.
Figure 2. I2D-Loc network structure
I2D-Loc
Statistics
Figure 3. Qualitative results on the KITTI dataset. Point clouds are projected using the initial poses and overlapped with the RGB images (First column). After estimating the flow using I2D-Loc, initial depth images are warped to overlapped with RGB (Second column). The third column is the depth images projected based on the ground truth pose. The warped depth images have the best structural consistency with RGB images and are most similar to ground truth.
Table 1. Performance comparison on KITTI, Argoverse, and Lyft5 datasets.
Download (Release soon)
1. I2D-Loc [Code & pretrained models]
2. Datasets: Since the dataset is very large and generated from [KITTI odometry dataset], we will realease the script on how to generate the dataset.
Video demos
2D to 3D localization demos using I2D-Loc
Left: random initialization; right: initialization using the pose of the previous frame in continous video.
Related Work
Our work is built based on the previous work including: CMRNet [1], CMRNet++ [2]. If you found our work helpful, consider citing these works as well.
Main References
Cmrnet: Camera to lidar-map registration
[paper]
Daniele Cattaneo, Matteo Vaghi, Augusto Luis Ballardini, Simone Fontana, Domenico Giorgio Sorrenti, Wolfram Burgard
IEEE Intelligent Transportation Systems Conference (ITSC), 2019.
CMRNet++: Map and Camera Agnostic Monocular Visual Localization in LiDAR Maps
[paper]
Daniele Cattaneo, Domenico Giorgio Sorrenti, Abhinav Valada
IEEE ICRA 2020 Workshop on Emerging Learning and Algorithmic Methods for Data Association in Robotics (ICRA), 2020.
HyperMap: Compressed 3D Map for Monocular Camera Registration
[paper]
Ming-Fang Chang; Joshua Mangelson; Michael Kaess; Simon Lucey
IEEE International Conference on Robotics and Automation (ICRA), 2021.